Ngôn Ngữ Lập Trình Hive Là Gì? Cách Thức Làm Việc Của Hive!
Sau khi đã cùng chúng tôi phân tích về BigData ở các bài viết trước, chắc hẳn các bạn đã có cái nhìn tổng quát nhất về nó rồi phải không? Ngoài ra, liên quan đến BigData, chúng tôi cũng đã có bài viết về công nghệ Hadoop, biết được cơ chế hoạt động của MapReduce, các ứng dụng bên trong của Hadoop gồm những gì? Và ở bài viết tiếp theo này, chúng ta sẽ cùng nhau tìm hiểu thêm một thành phần bên trong Hadoop nữa, đó là ngôn ngữ lập trình Hive. Vậy Hive là gì? HiveSQL là gì? Đặc trưng, kiến trúc và cách làm việc của Hive? Và Ưu điểm của Apache Hive là gì? Tất cả những thông tin trên sẽ được chúng tôi phân tích thật kỹ đến cho các ban, nào cùng nhau bắt đầu nhé!
Ngôn ngữ lập trình Hive là gì?
[caption id="attachment_1105" align="aligncenter" width="750"] Ngôn ngữ lập trình Hive là gì?[/caption]
Ngôn ngữ lập trình Hive là gì?[/caption]
Hive không phải là một cơ sở dữ liệu theo kiểu mối quan hệ, không phải là một thiết kế để xử lý các giao dịch online (OLTP – Online Transaction Processing), và cũng không phải là một ngôn ngữ cho các truy vấn thời gian thực… Mà ngôn ngữ lập trình Hive chính là công cụ cơ sở hạ tầng để xử lý dữ liệu có cấu trúc bên trong công nghệ Hadoop. Vị trí của nó là nằm trên đỉnh của Hadoop để tóm tắt, truy vấn và phần tích dữ liệu được dễ dàng hơn. Bạn có biết, lúc đầu Hive được phát triển bởi ai không, vâng, đó chính là gã khổng lồ mạng xã hội facebook. Nhưng sau đó, Apache đã lấy và phát triển thành mã nguồn mở như bây giờ và đặt tên là Apache Hive. Hiện nay, có rất nhiều công ty và tập đoàn lớn sử dụng Hive, như Amazon, Alibaba, Nike…
Bạn đọc tham khảo thêm: Hot job python lương cao chế độ đãi ngộ tốt Hot job java lương cao chế độ đãi ngộ tốtHiveSQL (hay được gọi tắt là HQL) là gì ?
Cũng giống như SQL, ngôn ngữ truy vấn Hive cũng cung cấp các toán tử cơ bản để xử lý cơ sở dữ liệu, HiveSQL có thể tạo và quản lý các tables và partitions dễ dàng, bên cạnh đó, nó cũng hỗ trợ các toán tử Relational, Logical, Arithmetic, Evaluate functions, và nhiều các loại toán tử khác nữa. Phương thức hoạt động của HiveSQL là tải về nội dung của một table từ thư mục cục bộ hoặc kết quả của các câu truy vấn đến thư mục HDFS.
Các bạn có thể tham khảo ví dụ sau để dễ hiểu hơn (thật quen thuộc phải không nào !)
SELECT upper(name), salesprice FROM sales; SELECT category, count(1) FROM products GROUP BY category;
Đặc trưng của Hive
- Thứ 1 nó được thiết kế dành cho OLAP
- Thứ 2: nó lưu trữ các lược đồ trong cơ sở dữ liệu và xử lý các dữ liệu này bên trong HDFS
- Thứ 3: nó cung cấp ngôn ngữ kiểu SQL để truy vấn cơ sở dữ liệu được thuận lợi và dễ dàng, và được gọi là HiveSQL (hay HQL)
- Thứ 4: chính vì sử dụng ngôn ngữ kiểu SQL, nên trông Hive rất quen thuộc, dễ dàng sử dụng nhanh chóng đối với các lập trình viên mới bắt đầu và đặc biệt có khả năng mở rộng.
Ở phần tiếp theo của bài viết, cũng là phần rất quan trọng về Hive, đó chính là kiến trúc và cách làm việc của nó, các bạn chú ý đọc kỹ và nếu có cơ hội làm việc với nó, hãy thực hành thật nhiều nhé !
Kiến trúc của Hive
Sơ đồ dưới đây miêu tả chi tiết về kiến trúc của ngôn ngữ lập trình Hive, bạn quan sát thật kỹ, sau đó chúng ta sẽ cùng nhau đi phân tích một số thành phần chính của nó nhé!
[caption id="attachment_1099" align="aligncenter" width="750"]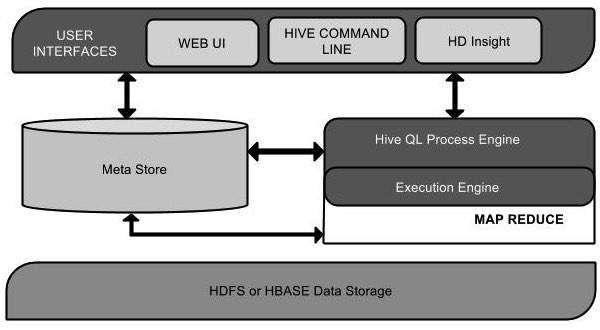 Kiến trúc của ngôn ngữ lập trình Hive[/caption]
Kiến trúc của ngôn ngữ lập trình Hive[/caption]
Kiến trúc của Hive có rất nhiều thành phần khác nhau, tuy nhiên, có 5 thành phần chính được sử dụng nhiều nhất dưới đây:
- Thành phần quan trọng đầu tiên với tên gọi User Interface: Đây chính là giao diện người dùng mà Hive hỗ trợ, bao gồm: Hive Web UI, Hive command line và Hive HD Insight, nó giúp tạo ra sự tương tác giữa người dùng với HDFS.
- Thành phần thứ 2. Meta Store: đây chính là nơi mà Hive chọn các máy chủ cơ sở dữ liệu để lưu trữ như: các loại lược đồ, các metadata, các cột, các bảng, các loại dữ liệu trong một bảng, một cột và dữ liệu ánh xạ của HDFS.
- Thành phần 3. HiveQL Process Engine: HiveQL làm việc tương tự nhe SQL để truy vấn các thông tin về lược đồ trên hệ thống. Ngoài ra, đây còn là một phương pháp nhằm thay thế cho chương trình MapReduce. Vì thế, các lập trình viên thay vì phải viết chương trình MapReduce bằng Java tương đối phức tạp và mất khá nhiều thời gian, thì họ có thể viết những câu truy vấn bằng HiveQL để xử lý công việc được dễ dàng hơn.
- Thành phần thứ 4. Execution Engine: đây là phần kết hợp giữa 2 công cụ xử lý: HiveQL + MapReduce, và nó chính là công cụ thực thi Hive Execution Engine. Công cụ này giúp thực thi và xử lý các câu truy vấn dữ liệu.
- Và cuối cùng, là thành phần thứ 5. HDFS hoặc HBASE: đây chính là hệ thống các tệp phân tán của Hadoop. Và HBASE chính là các kỹ thuật dùng để lưu trữ dữ liệu vào hệ thống các tệp phân tán đó.
Cách thức làm việc của Hive
Bạn hãy quan sát sơ đồ dưới đây, nó mô tả quy trình làm việc giữa Hive và Hadoop.
[caption id="attachment_1100" align="aligncenter" width="750"]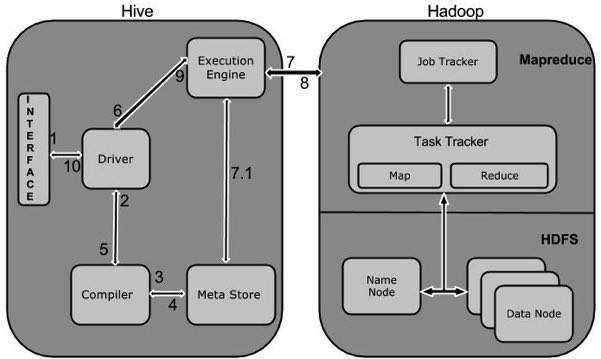 Quy trình làm việc của Hive và Hadoop[/caption]
Quy trình làm việc của Hive và Hadoop[/caption]
- Bước 1: Thực thi các dòng lệnh query: giao diện sử dụng của Hive giống như Command line, hoặc các giao diện người dùng web, gửi truy vấn đến trình điều khiển để thực thi các dòng lệnh
- Bước 2: Nhận kế hoạch: trình điều khiển với sự trợ giúp của trình biên dịch, sau đó phân tích các cú pháp truy cấp để kiểm tra các cú pháp, các kế hoạch và yêu cầu truy vấn.
- Bước 3: Nhận metadata: các trình biên dịch sẽ gửi yêu cầu nhận metadata đến Metastore.
- Bước 4: gửi kế hoạch: các trình biên dịch sau khi kiểm tra thật kỹ các yêu cầu sẽ gửi lại kế hoạch cho trình điều khiển xử lý tiếp. Và đến đây, thì việc phân tích cú pháp và biên dịch một truy vấn đã được hoàn tất.
- Bước 5: Thực hiện kế hoạch: trình điều khiển sẽ gửi kế hoạch ở phía trên đến các công cụ thực thi.
- Bước 6: Thực thi công việc: MapReduce sẽ có nhiệm vụ thực thi các công việc trên. Công cụ này sẽ gửi công việc đến các JobTracker ở bên trong node Name, sau đó nó gán công việc này cho các TaskTracker.
- Bước 7: các hoạt động của metadata: trong quá trình thực hiện, các công cụ thực thi sẽ triển khai các hoạt động của metadata với Metastore.
- Bước 8: Lấy kết quả: các công cụ thực thi sẽ lấy kết quả từ các node Data
- Bước 9: Gửi kết quả: sau khi thực thi xong, các công cụ sẽ gửi kết quả đến trình điều khiển, cuối cùng, các trình điều khiển sẽ gửi toàn bộ kết quả xử lý được đến giao diện Hive.
- Bước 10: các lập trình viên có thể sử dụng các kết quả được gửi đến Hive để phục vụ cho công việc của mình và hoàn thành các bước xử lý dữ liệu tiếp theo.
Trên đây là toàn bộ các thức làm việc của ngôn ngữ lập trình Hive, và ở phần cuối của bài viết này, chúng ta sẽ tìm hiểu thêm những ưu điểm vượt trội của Apache Hive, biến nó trở thành một công cụ hỗ trợ đắc lực nhất của hệ thống Hadoop.
Những ưu điểm vượt trội của Apache Hive
- Nó là một cơ sở dữ liệu SQL thực, với bộ dữ liệu rất lớn.
- Nó được tích hợp công cụ BI, các trường sử dụng EDW, bảng ACID, ngoài ra nó còn tích hợp cả Hbase giúp xử lý thông tin, dữ liệu chính xác và nhanh chóng hơn.
- Nó hỗ trợ Spark mạnh mẽ, tương tác tốt với Druid, ngoài ra với cơ chế bảo mật dữ liệu mạnh mẽ, Apache Hive sẽ giúp ích rất nhiều cho các lập trình viên trong vấn đề bảo mật thông tin người dùng.
- Apache Hive hỗ trợ lưu trữ các loại tệp dữ liệu khác nhau trên HDFS bao gồm: Apache ORC, Apache Parquet, CSV, JSON, ACID
- Kết hợp SQL trên Hadoop (HPL & SQL)
ITNavi - Nền tảng kết nối việc làm
Nguồn: Ngôn Ngữ Lập Trình Hive Là Gì? Cách Thức Làm Việc Của Hive!