Crawl dữ liệu Website sử dụng kỹ thuật phân tích cú pháp XML bằng PHP
Xin chào các bạn, hôm nay chúng ta tìm hiểu về một trong những ngôn ngữ lập trình lâu đời và phổ biến nhất hiện nay, đó chính là PHP. Chắc chắn là dân lập trình, các bạn ai cũng đều học qua và biết đến ngôn ngữ này rồi phải không. Hiện nay, tất cả các dự án web dù lớn hay nhỏ đều được xây dựng từ chính ngôn ngữ lập trình này. Và trong bài viết hôm nay, chúng tôi xin giới thiệu đến với các bạn, một trong những ứng dụng rất phổ biến và cũng là ứng dụng được các lập trình viên rất ưa thích, đó chính là cách crawl dữ liệu website sử dụng kỹ thuật phân tích cú pháp xml bằng php. Quả thật, đây là một ứng dụng vô cùng quan trọng, nói khó thì cũng không đến nỗi quá khó, nhưng lại không hề dễ dàng một chút nào đâu nhé, hãy cùng chúng tôi bắt đầu theo từng bước dưới đây! Cố gắng đọc thật kỹ, chắc chắn các bạn sẽ thực hiện thành công cho website của mình!
Crawl dữ liệu website là gì?
Bạn có bao giờ tự hỏi, làm sao lấy được toàn bộ những dữ liệu khổng lồ từ những trang tin tức lớn như zing.vn, vnexpress.net, hay các sản phẩm từ các trang thương mại điện tử lớn như Amazon, giả sử nếu bạn siêng năng lắm, làm việc chăm chỉ bằng cách vào từng trang tin, từng sản phẩm để copy về website của mình, thì cũng tốn rất nhiều thời gian và công sức mới có thể làm được một phần nào đó của công việc. Chính vì thế, lúc này chúng ta cần đến một kỹ thuật khá đặc biệt, đó chính là kỹ thuật Crawl, chúng ta cùng tìm hiểu về kỹ thuật này một chút trước khi bắt tay vào thực hiện nhé !
[caption id="attachment_1261" align="aligncenter" width="638"]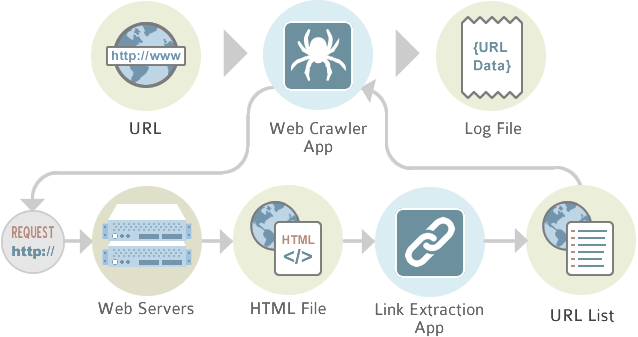 Kỹ thuật crawl dữ liệu website là kỹ thuật để thu thập dữ liệu khá phổ biến[/caption]
Kỹ thuật crawl dữ liệu website là kỹ thuật để thu thập dữ liệu khá phổ biến[/caption]
Kỹ thuật crawl dữ liệu website là kỹ thuật để thu thập dữ liệu khá phổ biến, Google bot cũng là một hình thức của crawler. Kỹ thuật crawler có rất nhiều ứng dụng thực tế như: Xây dựng ứng dụng đọc báo bằng cách crawl dữ liệu website từ các báo lớn, crawl các thông tin tuyển dụng như ITNavi.v.v… Để tạo ra được một web crawler có rất nhiều cách, và cũng có vô số framework hỗ trợ. Ví dụ như Python thì có Scrapy rất nổi tiếng. Trong bài viết này chúng ta sẽ cùng nhau tìm hiểu kỹ thuật crawler dữ liệu website sử dụng kỹ thuật phân tích cú pháp XML bằng PHP.
Đầu tiên, mình sẽ cùng các bạn tìm hiểu xem crawler website là gì ?. Tóm lại thì web crawler là kỹ thuật thu thập dữ liệu từ các đường links cho trước trên các website trên mạng. Nếu trong quá trình thu thập dữ liệu, bạn chỉ chắt lọc những thông tin cần thiết cho nhu câu cầu bạn thì người ta gọi là web Scaping. Hai khái niệm web crawler và web scaping về cơ bản giống nhau.
Ví dụ với trang tiki.vn, kỹ thuật web crawling sẽ thu thập toàn bộ nội dung của trang web này (tên sản phẩm, mô tả sản phẩm, giá sản phẩm, hướng dẫn sử dụng, các đánh giá và bình luận về sản phẩm,…). Tuy nhiên, web scaping thì có thể chỉ thu thập một số thông tin cần thiết với bạn như: chỉ thu thập giá sản phẩm để làm ứng dụng so sánh giá.
Những dữ liệu khi crawl có thể được lưu trữ trong cơ sở dữ liệu của bạn để phục vụ việc phân tích hoặc sử dụng với mục đích khác nhau. Hoặc có thể show trực tiếp ra trang web như các web tin tức, dự báo thời tiết,...
Bạn đọc tham khảo thêm:Tuyển dụng php laravel lương cao chế độ hấp dẫn
Việc làm java web developer lương cao chế độ hấp dẫnHướng dẫn thực hành Crawl dữ liệu từ trang VNExpress Rss
Trang web VNExpress cung cấp cho các bạn một danh sách tin tức rất đầy đủ và cập nhật theo thời gian bằng định dạng Rss là trang https://vnexpress.net/rss. Nào hãy bắt tay vào thôi.
Bước 1: Cài đặt môi trường
PHP chạy trên môi trường Webserver và lưu trữ dữ liệu thông qua hệ quản trị cơ sở dữ liệu nên PHP thường đi kèm với Apache, MySQL. Và đây là link cài đặt môi trường cho các bạn https://hourofcode.vn/cai-dat-moi-truong-cho-php/.
Sau khi đã cài đặt môi trường rồi thì để code PHP cần 1 IDE tốt để code ở đây mình chọn Sublime Text
Bước 2: Tạo folder chứa trang web
Sau khi đã cài môi trường thành công (ở đây mình cài XAMPP) các bạn vào đường dẫn C:\xampp\htdocs\ tạo 1 folder mới và đặt tên cho nó mình sẽ đặt là CodeLearnNews.
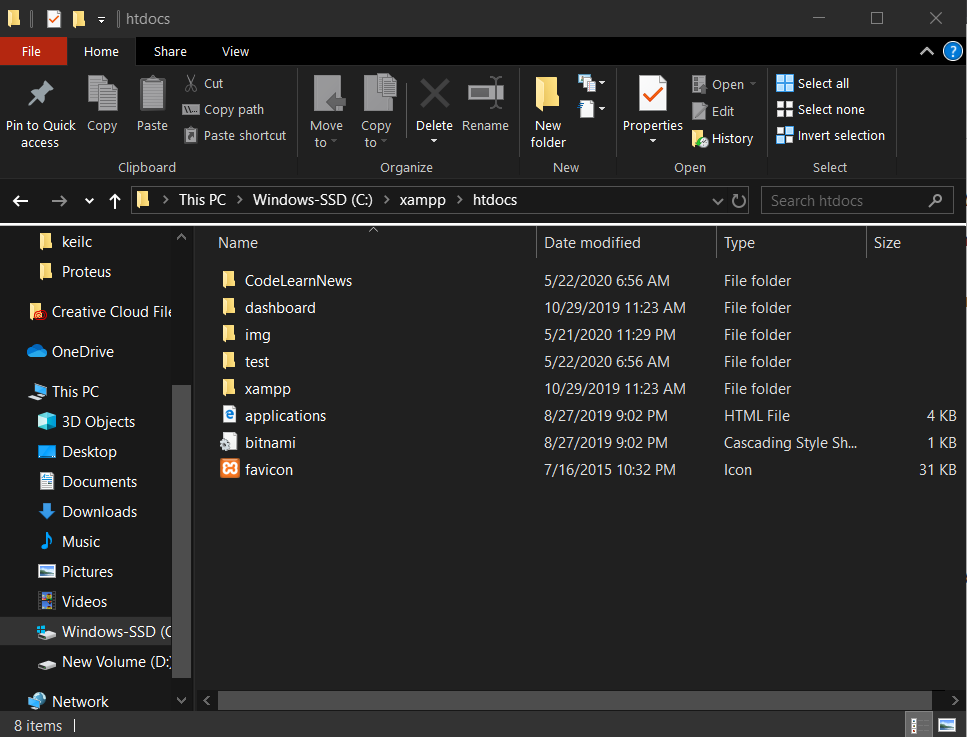 Sau đó tạo 1 file index.php bên trong folder CodeLearnNews trong CodeLearnNews.
Sau đó tạo 1 file index.php bên trong folder CodeLearnNews trong CodeLearnNews.
Sau đó add folder CodeLearnNews vào Sublime Text rồi tạo 1 folder mới nữa với tên getdata bên trong folder CodeLearnNews, tạo file mới với tên get_data_home.php để lấy dữ liệu cho trang chủ của mình.
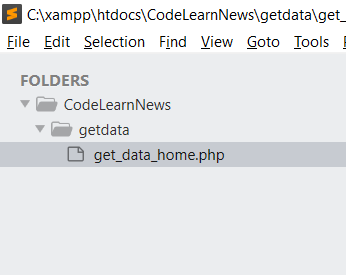
Bước 3: Code
Các bạn vào file get_data_home.php chúng ta sẽ lấy dữ liệu tin mới nhất.
<?php $url='https://vnexpress.net/rss/tin-moi-nhat.rss'; $lines_array=file($url); $lines_string=implode('',$lines_array); $xml = simplexml_load_string($lines_string); if ($xml === false) { echo "Failed loading XML: "; foreach(libxml_get_errors() as $error) { echo "<br>", $error->message; } }else{ echo $xml->asXML(); } ?>
Bước 4: Chạy trên trình duyệt
Dữ liệu của chúng ta là dữ liệu dạng XML.. Kết quả.
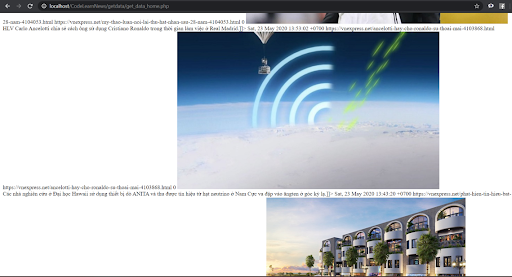
Qủa thật, kỹ thuật này rất đơn giản phải không, ở bài viết tiếp theo, chúng tôi sẽ giới thiệu đến cho các bạn nhiều kỹ thuật Crawl tinh vi hơn nữa, từ những trang thông tin thương mại điện tử lớn nhất trên thế giới như Amazon, Alibaba, hoặc Tiki của Việt Nam. Hy vọng thông qua bài viết này, các bạn có thể lấy được những thông tin bổ ích nhất, lấy được những sản phẩm được cập nhật mới nhất để làm mới website của mình, các bạn cứ code và làm đi làm lại một vài lần, chắc chắn các bạn sẽ hiểu và thực hiện một cách thành thục nhất. Chúc các bạn thành công !
Bạn đọc tham khảo thêm:Design Patterns là gì?Lý do cần sử dụng Design Patterns
ITNavi - Nền tảng kết nối việc làm
Nguồn: Crawl dữ liệu Website sử dụng kỹ thuật phân tích cú pháp XML bằng PHP